Storage Management & Indexing
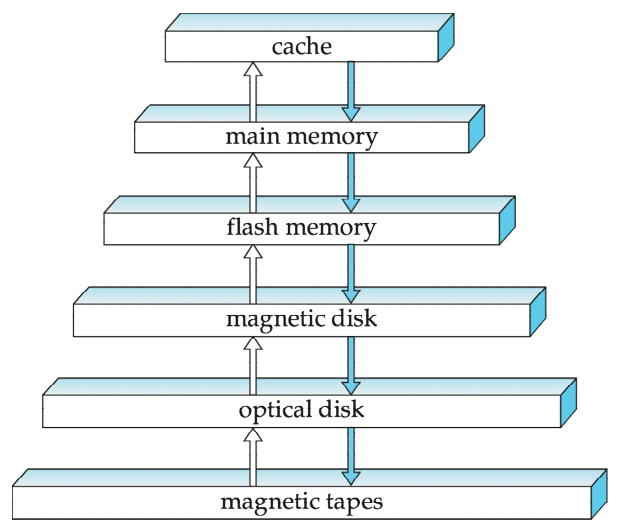
Storage hierarchy
Magnetic hard disk

각 platter의 전면부와 후면부에 데이터 저장하므로, (platter 개수) * 2 개 면에 데이터를 저장
각 면의 head로 데이터를 읽거나 씀
각 head는 arm을 통해 arm assembly에 연결되어 있음
각 track마다 cylinder 가짐
한 platter에는 50K ~ 100K 개 track
한 sector의 물리적 단위는 주로 512 bytes
Access time
seek time: 2~20 ms
rotational delay: 4~11 ms
data transfer rate: 50~200M / sec
Sector vs. Block
sector = physical unit
block = logical unit

크기에 따라 다르지만, 위와 같이 512 bytes sector / 1KB block인 경우 1개 block에 2개 sector가 들어가는 것
데이터베이스에 저장된 데이터를 block 단위로 나누어 다룸
Storage access

disk: 실제 데이터가 저장되어 있는 곳
main memory: 데이터에 작업하기 위해 필요한 데이터를 갖다놓아야 하는 곳
table dictionary: 이 블럭의 튜플들이 어떤 table에 속하는 튜플들인지
row dictionary: 이 블럭의 튜플들이 어떤 row에 속하는 튜플들인지
데이터 저장 및 이동은 블럭 단위로 이루어진다. fixed-length storage unit
효율적으로 작동하기 위해 disk ↔ main memory 간 block transfer 횟수를 최소화하려 함
Buffer manager
main memory의 database buffer에 disk에서 가져온 데이터 복사본 블럭을 넣어둠으로써 disk에 접근하는 횟수를 줄일 수 있다. buffer manager는 이 buffer를 관리하는 역할을 함.
buffer의 용량은 한정되어 있기 때문에 buffer manager는 buffer가 가득 차면 어떤 블럭을 지울지 선택해야 하는데, 이때 다음과 같은 블럭의 종류를 고려하게 됨:
- read only block: disk에 반영시킬 필요 없음. 읽기 전용이기 때문에 buffer에 있는 이 블럭과 disk에 있는 원본 블럭은 같은 내용이기 때문.
- dirty block: buffer에서 블럭에 수정 작업이 이루어졌으나 아직 disk에 반영되지 않았기 때문에 함부로 삭제할 수 없고, 반드시 disk에 반영한 후 삭제해야 하는 블럭.
- pinned block: 아직 수정 작업 중이기 때문에 삭제하면 안 되는 블럭.
어떤 프로그램이 작동 중 필요한 데이터가 있을 경우, buffer manager를 호출한다.
- 해당 데이터가 있는 블럭이 buffer에 있는 경우, buffer manager는 그 주소를 리턴.
- buffer에 없는 경우, ...
- buffer에 새 블럭이 들어올 자리를 할당한다. (새 블럭이 들어올 자리가 없는 경우, 기존에 있는 블럭을 삭제한다)
- disk에서 buffer로 필요한 블럭을 읽어온다.
- 그 주소를 리턴한다.
Buffer-replacement policies
기본적으로 LRU strategy 채택: 사용한 지 가장 오래된 블럭 (least recently used block)을 삭제
과거 블럭을 참조한 패턴을 추후 참조 패턴의 예측치로 활용한다는 아이디어를 배경으로 하는 것.
반복적으로 데이터를 스캔하는 패턴이 있는 경우, LRU strategy는 항상 최선의 전략은 아님.
실제로는 query optimizer에 의해 제공되는 정보를 활용한 mixed strategy를 채택하는 것이 좋음
Query Processing & Optimization
Query processing

1. Parsing & Translation
입력받은 query의 syntax를 체크하고, query를 relational algebra 형식으로 변환
2. Optimization
logical query execution plan 생성
3. Evaluation
여러 execution plan들의 결과 size와, 개별 plan들에 필요한 비용을 계산해 그중 최소 비용이 필요한 plan을 채택
Expression results size estimation
notations
- $n_r$ : relation r에 있는 총 튜플 개수
- $b_r$ : relation r의 모든 튜플을 저장하는 데 필요한 블럭 개수
- $l_r$ : r의 튜플의 크기
- $f_r$ : 한 블럭에 r의 튜플을 몇 개까지 넣을 수 있는지 (blocking factor)
- $V(A, r)$ : r의 attribute A의 distinct value 개수
1. Selection operation
$$\sigma_{A=v}(r)$$
relation r에서 attribute A=v인 record들만 select
연산 결과 size = 선택된 records 개수 = $n_r / V(A, r)$
단, A가 key attribute인 경우: size estimation = 1
key attribute는 모든 튜플이 서로 중복된 값을 갖지 않기 때문
example

- $n_r$ = 12
- V(name, student) = 12
- V(dept_name, student) = 6
(1) $\sigma_{\mathrm{name=Levy}}(\mathrm{student})$ 연산의 size estimation
name은 key attribute
$n_r /$ V(name, student) = 12/12 = 1
(2) $\sigma_{\mathrm{dept_name=Physics}}(\mathrm{student})$ 연산의 size estimation
$n_r /$ V(dept_name, student) = 12/6 = 2
2. Join operation
$$R \bowtie S$$
case 1. R∩S가 한 테이블(R)의 primary key인 경우: join 연산 결과는 R의 총 튜플 개수보다 작거나 같음
case 2. R∩S가 S가 R을 참조하는 foreign key인 경우: join 연산 결과는 R의 총 튜플 개수와 같음
case 3. R∩S가 R과 S 둘 중 어느 테이블의 key도 아닌 경우: 다음 두 가지 계산 결과를 비교해 더 작은 값을 size estimation으로 함
- assume that every tuple in R produces tuples in R ⨝ S: $\frac{n_r * n_s} {V(A, r)}$
- assume that the reverse is true (every tuple in S ...): $\frac{n_r * n_s} {V(A, s)}$
example

r ⨝ s 의 size estimation
r∩s = {B} 는 r과 s 모두의 key attribute가 아니므로, 다음 두 계산 결과값을 비교:
$\frac{n_r * n_s} {V(A, r)}$ = 5*8 / 4 = 10
$\frac{n_r * n_s} {V(A, s)}$ = 5*8 / 5 = 8
따라서, r ⨝ s 연산 결과 size를 8이라고 추정
Query cost estimation
$$b * t_T + S * t_S$$
- $b$ : disk에서 메모리로 가져온 블럭 개수
- $t_T$ : disk에서 메모리로 한 블럭 transfer 하는 데 소요되는 시간
- $S$ : seek 횟수
- $t_S$ : seek 한 번 하는 데 소요되는 시간
쿼리 처리 비용에는 위 요소 외에도 CPU cost 등 영향을 미치는 요소가 더 많이 있지만, 이 두 요소가 가장 큰 부분을 차지하기도 하고 계산의 용이성을 위해 disk로부터의 block transfer 횟수와 seek 횟수만을 고려해 비용을 추정
seek 횟수는 블럭이 저장된 방식에 따라 달라질 수 있음.
예를 들어, 4개 블럭 (b1, b2, b3, b4)로 구성된 테이블이 있고 이 순서대로 디스크에서 메모리로 읽어온다고 할 때

<1>처럼 블럭이 차례로 저장되어 있는 경우:
- 헤드를 b1 위치로 옮기고 b1 읽음 // 1 seek, 1 block transfer 발생
- b2를 읽을 차례인데, b1 읽은 후 헤드는 이미 b2 위치에 있으므로 그대로 b2 읽음 // 1 block transfer 발생
- 마찬가지로 헤드가 이미 b3 위치에 있으므로 그대로 b3 읽음 // 1 block transfer 발생
- 마찬가지로 헤드가 이미 b4 위치에 있으므로 그대로 b4 읽음 // 1 block transfer 발생
∴ n개 블럭을 읽기 위해 1 seek, n block transfer 발생
<2>처럼 블럭이 랜덤하게 저장되어 있는 경우:
각 블럭을 읽을 때마다 헤드를 해당 블럭이 있는 위치로 옮기고 블럭을 읽어야 함
∴ n개 블럭을 읽기 위해 n seek, n block transfer 발생
1. cost estimation of selection operation
select operation은 linear search 방식으로 이루어짐 (처음부터 차례로 쭉 검색)
key attribute 아닌 경우:
$b_r$ block transfer, 1 seek
key가 아니라서 여러 개 존재할 수 있기 때문에, 모든 블럭의 튜플을 살펴봐야 함
key attribute인 경우:
$(b_r / 2)$ block transfer, 1 seek
최선의 경우 첫 번째 블럭에서 찾을 수 있고, 최악의 경우 모든 블럭을 살펴봐야 하기 때문에 두 경우를 평균낸 것으로 비용 추정
2. cost estimation of join operation
nested-loop join (r의 첫번째 튜플과 s의 첫번째 튜플 보기 → 조건 맞으면 join → r의 첫번째 튜플과 s의 두번째 튜플 → s의 세번째 튜플 → ….. → r의 두번째 튜플과 s의 첫번째 튜플 → …)
각 테이블 (r, s)의 블럭을 1개씩만 메모리에 올려놓을 수 있는 상황이라고 가정
r 입장에서: r 블럭 개수만큼 block transfer, r 블럭 개수만큼 seek
s 입장에서: (r 튜플 개수) * (s 블럭 개수) 만큼 block transfer, r 튜플 개수만큼 seek
∴ 합해서, $n_r * b_s + b_r$ block transfer, $b_r + n_r$ seek
본 포스트 내용은 고려대학교 컴퓨터학과 "데이터베이스" 강의 내용 일부를 개인 공부 목적으로 정리한 것입니다.
'computer science > 데이터베이스' 카테고리의 다른 글
| Concurrency Control (0) | 2024.01.26 |
|---|---|
| Transaction (0) | 2024.01.25 |
| Relational Algebra (관계대수) (0) | 2024.01.08 |
| Basics of Relational Model (0) | 2024.01.06 |
| Database Introduction (0) | 2024.01.06 |



